Suivre l’impact de la crise de la COVID-19 au moyen de Twitter et en faire une base de données, c’est le défi que se sont lancé Muhammad Abdul-Mageed, professeur assistant à UBC, et son équipe. Ce projet, nommé Mega-cov Database, regroupe plus d’un milliard de gazouillis en 104 langues, collectés dans 268 pays auprès de plus d’un million d’utilisateurs.
Les intérêts sont multiples, explique M. Abdul-Mageed : « le projet Mega-cov peut être utilisé pour étudier différentes questions qui peuvent s’avérer intéressantes tant pour les scientifiques que les gouvernements, ceux qui décident des politiques, les journalistes, les entrepreneurs et autres professionnels », avant de préciser qu’il faut comprendre que l’interprétation des résultats de la base de données doit être perçue à l’aune des conditions d’utilisation de Twitter. En effet, la plateforme peut interdire certains contenus trop polarisants ou susceptibles de représenter un danger pour la santé, par exemple.
Des applications possibles dans (presque) tous les domaines
Parmi les utilisations possibles, le projet Mega-cov permet de suivre l’évolution du discours des politiciens, leurs degrés d’empathie envers les divers acteurs de la société, et s’ils tentent de déformer les faits pour servir leurs propres intérêts. Il permet de voir à qui s’adressent ces derniers, s’il s’agit de leur base ou du public en général. On peut ainsi comparer les classes politiques des différents pays à travers le monde.
Il est également possible de voir quelles sont les populations satisfaites ou non des mesures prises par les gouvernants. Par exemple au Canada, quelles sont les provinces où l’approbation est la plus haute, et quelles décisions sont les mieux perçues. Dans un autre domaine, on voit aussi toute la désinformation, ce que les gens croient savoir de la COVID-19 et ce qu’ils partagent, notamment les fake news et celles qui ont le plus de succès, ce qui peut permettre de mieux les combattre par la suite.
Mega-cov permet aussi de traiter de sujets sociétaux comme le racisme et les discours haineux. La communication négative est ainsi passée au crible, et on peut y retrouver les motivations de leurs auteurs, mais aussi la façon dont ils évoluent dans les différents pays. Pour le Canada, on peut cibler précisément quels sont les secteurs de la société concernés et les provinces les plus touchées.

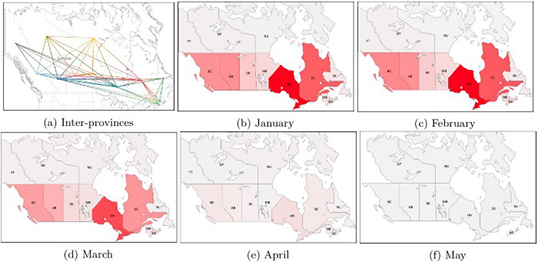
Deux illustrations du projet Mega-cov : la première représente la mobilité au Canada pendant la crise de janvier à mai et la seconde les mots clé de Twitter. | Photo de M. Abdul-Mageed et UBC
Sur un plan plus pratique, le travail de l’équipe de M. Abdul-Mageed permet de se faire une idée de la façon dont la COVID-19 a affecté la mobilité à travers le monde. On peut ainsi suivre presque au jour le jour la façon dont l’activité s’est ralentie pays par pays et les résultats peuvent parfois être… inattendus. On retrouve aussi les préoccupations de tous les jours et on note les différences que l’on perçoit entre les grandes villes et les plus modestes. La base de données permet également de mettre en lumière les émotions dominantes dans la population, comment elles décrivent leur bien-être et leur santé.

Muhammad Abdul-Mageed, professeur assistant à UBC. | Photos de M. Abdul-Mageed et UBC
Une méthodologie fiable ?
Interrogé sur la méthodologie employée pour constituer cette base de données, M. Abdul-Mageed nous explique : « Nous avons utilisé un programme fourni par Twitter qui permet de collecter jusqu’à 1% des données région par région, aussi bien pour les personnes physiques que pour les médias » et de continuer « nous avons ainsi des données depuis 2007, mais le projet Mega-cov se concentre sur les tweets depuis janvier 2020 ». Parce qu’ils travaillent en accord avec les règles d’utilisation de twitter, ces données sont anonymisées sauf pour celles qui proviennent des medias et ne peuvent être commercialisées. Les mots clefs utilisés varient grandement selon les langues : en français, on retrouve ainsi les termes « Covid, coronavirus, perdu, confinement, restez chez vous… municipales et Koh Lanta. » tandis qu’en anglais ces termes sont « Covid, coronavirus, shopmycloset, now playing, stay home et… Nintendo switch ».
Il y a ensuite énormément de travail de tri d’analyse que nous détaillons sur medium.com, qu’il s’agisse de la géolocalisation, de la période couverte, des profils des utilisateurs (vétérans, nouveaux venus, occasionnels…) et bien entendu des langues. (Le lien pour retrouver cette méthodologie, en anglais, est disponible sur notre site internet).
La base de données permet même d’analyser les gazouillis de pays dans lesquels Twitter est normalement interdit mais où les utilisateurs du réseau parviennent tout de même à se connecter (Chine, Corée du nord, Iran…) même si la représentativité de ces données est à relativiser étant donné leur rareté (un peu moins de 23 000 tweets pour la Chine, à peine plus de 1000 en Corée du Nord ; nous ne donnerons pas le nombre d’utilisateurs pour des raisons évidentes)
En résumé, et en dépit de toutes les réserves que l’on peut émettre sur le degré de fiabilité que l’on peut accorder à Twitter, le Mega-cov Database est une des toutes premières tentatives de photographier l’humanité dans son ensemble et sous toutes les coutures au moment d’une des crises les plus graves qui la menace depuis la guerre froide.


